publications
2026
- under reviewEvaluating misspelling patterns in gamified data: A sociodemographic analysis for linguistic researchAdele Loia, Gianluca Sperduti, and Marianna BolognesiIn under review, 2026
Misspellings are common in written language, but how they vary across writing tools and speaker profiles remains underexplored. This study investigates the relationship between sociodemographic factors and orthographic variation in a gamified environment. Specifically, it examines how age, occupation, education, and reading habits influence spelling variation during a linguistic production task. Data were collected through the mobile application Word Ladders, through which we collected 6700 word ladders from a variety of users. A detailed coding scheme was developed to classify different forms of divergence from the orthographic norm, including typographical deviations and non-standard spellings. Results of quantitative analyses reveal significant associations between sociodemographic profiles and misspellings patterns, with broader implications for linguistic research in naturalistic settings such as social media and gamified platforms. By identifying potential biases in data collection and interpretation, this study contributes to improving methodologies for studying written language and ensuring data quality in linguistic research.
- NLPJ
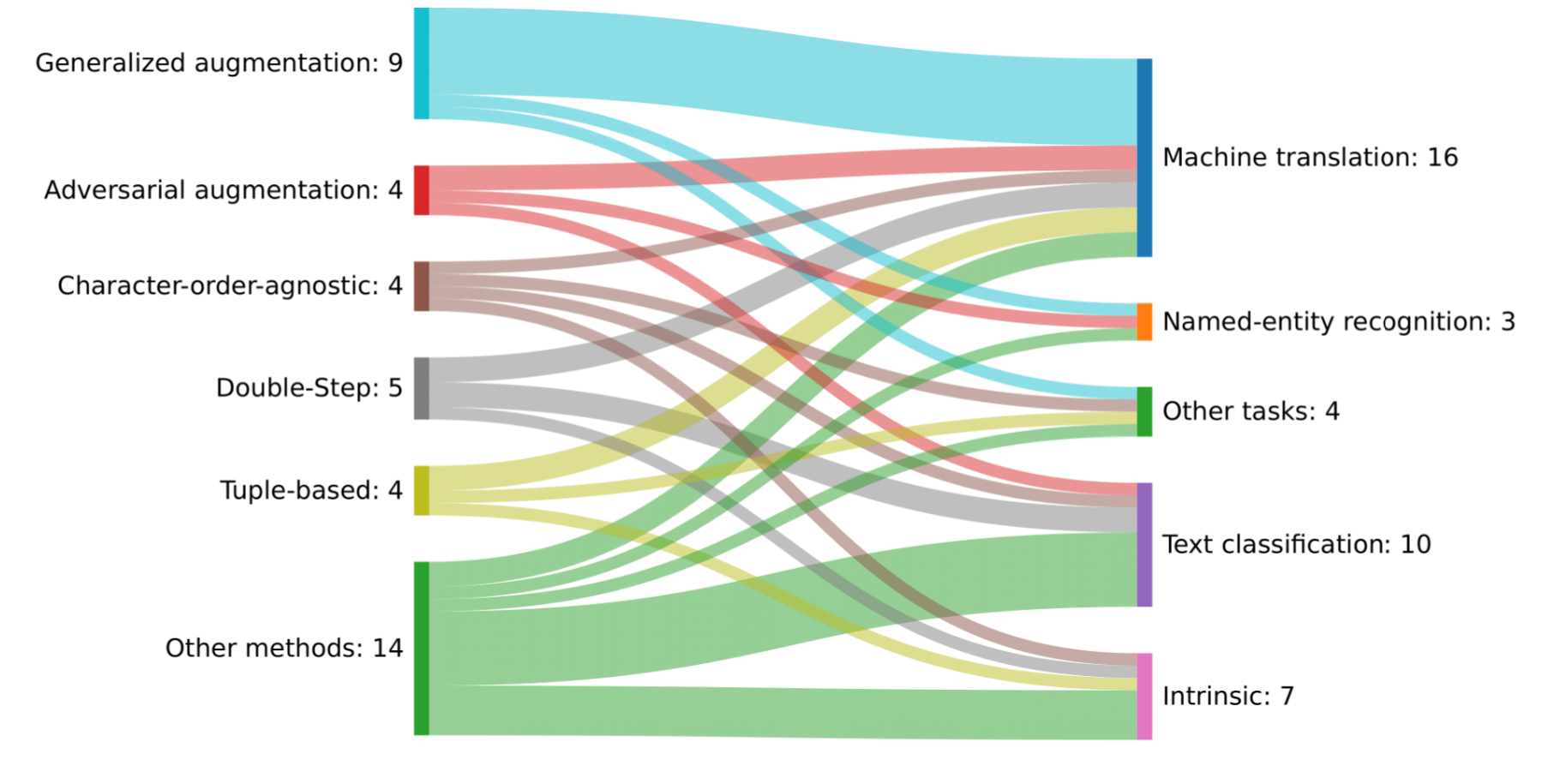 Misspellings in Natural Language Processing: A surveyGianluca Sperduti and Alejandro MoreoNatural Language Processing Journal, 2026
Misspellings in Natural Language Processing: A surveyGianluca Sperduti and Alejandro MoreoNatural Language Processing Journal, 2026This survey provides an overview of the challenges of misspellings in natural language processing (NLP). While often unintentional, misspellings have become ubiquitous in digital communication, especially with the proliferation of Web 2.0, user-generated content, and informal text mediums such as social media, blogs, and forums. Even if humans can generally interpret misspelled text, NLP models frequently struggle to handle it: this causes a decline in performance in common tasks like text classification and machine translation. In this paper, we reconstruct a history of misspellings as a scientific problem. We then discuss the latest advancements to address the challenge of misspellings in NLP. Main strategies to mitigate the effect of misspellings include data augmentation, double step, character-order agnostic, and tuple-based methods, among others. This survey also examines dedicated data challenges and competitions to spur progress in the field. Critical safety and ethical concerns are also examined, for example, the voluntary use of misspellings to inject malicious messages and hate speech on social networks. Furthermore, the survey explores psycholinguistic perspectives on how humans process misspellings, potentially informing innovative computational techniques for text normalization and representation. Finally, the misspelling-related challenges and opportunities associated with modern large language models are also analyzed, including benchmarks, datasets, and performances of the most prominent language models against misspellings. This survey aims to be an exhaustive resource for researchers seeking to mitigate the impact of misspellings in the rapidly evolving landscape of NLP.
- Machine LearningGSM-Identity: Evaluating Mathematical Reasoning in LLMs via Equivalence TransformationKajal Negi, Giovanni Puccetti, and Andrea EsuliMachine Learning, 2026
We introduce GSM-Identity, a pipeline to modify existing mathematical reasoning benchmarks by adding extra complexity to the questions while preserving their fundamental meaning. By systematically transforming numerical values in the GSM8K dataset into mathematically equivalent but less obvious expressions, we create a benchmark to measure Large Language Models (LLMs) mathematical understanding. We evaluate LLMs ranging from 7 billions to 72 billions parameters using multiple prompting strategies, including standard, notice-based, and chain-of-thought approaches. We find that Math oriented models can retain most of their performance on GSM8K when evaluated on GSM-Identity, while general purpose models show significant performance degradation. A comparison with human evaluations reveals that models in the 7 billion parameters range perform similar to humans when exposed to the kind of modifications we study, while models with more than 70 billion parameters are more accurate than humans in answering the questions and they are also more resilient to modifications. Our findings highlight GSM-Identity as a valuable tool for distinguishing reasoning from memorization, offering insights into the abilities of LLMs to understand higher level mathematical concepts.
- TISTA Multi-Perspective Evaluation of Mathematical Reasoning in Vision and Language ModelsKajal Negi, Giovanni Puccetti, and Andrea EsuliTransactions on Intelligent Systems and Technology, 2026
Large language models (LLMs) and multimodal large language models (MLLMs) are increasingly used for mathematical reasoning, yet their reliability is still largely assessed through conventional accuracy-based methods that fail to capture deeper aspects of reasoning and robustness. We argue that mathematical competence requires more than producing correct answers: a truly reasoning system should also give consistent answers to equivalent formulations of the same problem, reliably verify whether a proposed solution is correct, and recognize when a problem has no solution or admits multiple solutions. Accordingly, we propose a multi-faceted evaluation framework comprising four complementary tasks: (i) Answer Accuracy, the standard protocol; (ii) Identical-Question consistency, measuring whether a model returns the same answer for semantically equivalent questions; (iii) Answer Verification, assessing a model’s ability to judge the correctness of a given question–answer pair; and (iv) Non-unique Solvability detection, testing whether a model can identify problems that have no solution or infinitely many solutions. We evaluate 13 models from five model families (LLaVA-OneVision, InternLM-XComposer, Llama, Qwen, and VL-Rethinker) across five datasets. To support this evaluation, we introduce PaRallelMath, a geometry dataset of 782 samples arranged in mathematically identical visual pairs, and NoUni, a 300-sample dataset of problems with no unique solution. Our results show that all models exhibit measurable inconsistency on equivalent questions, display positive biases when verifying answers, and largely fail to detect unsolvable or under-determined problems, even when their standard accuracy is high. These findings highlight the limitations of accuracy-only evaluation and underscore the need for broader, multi-dimensional assessment of mathematical reasoning in (M)LLMs for greater reliabilityand usability.
2025
- ACL
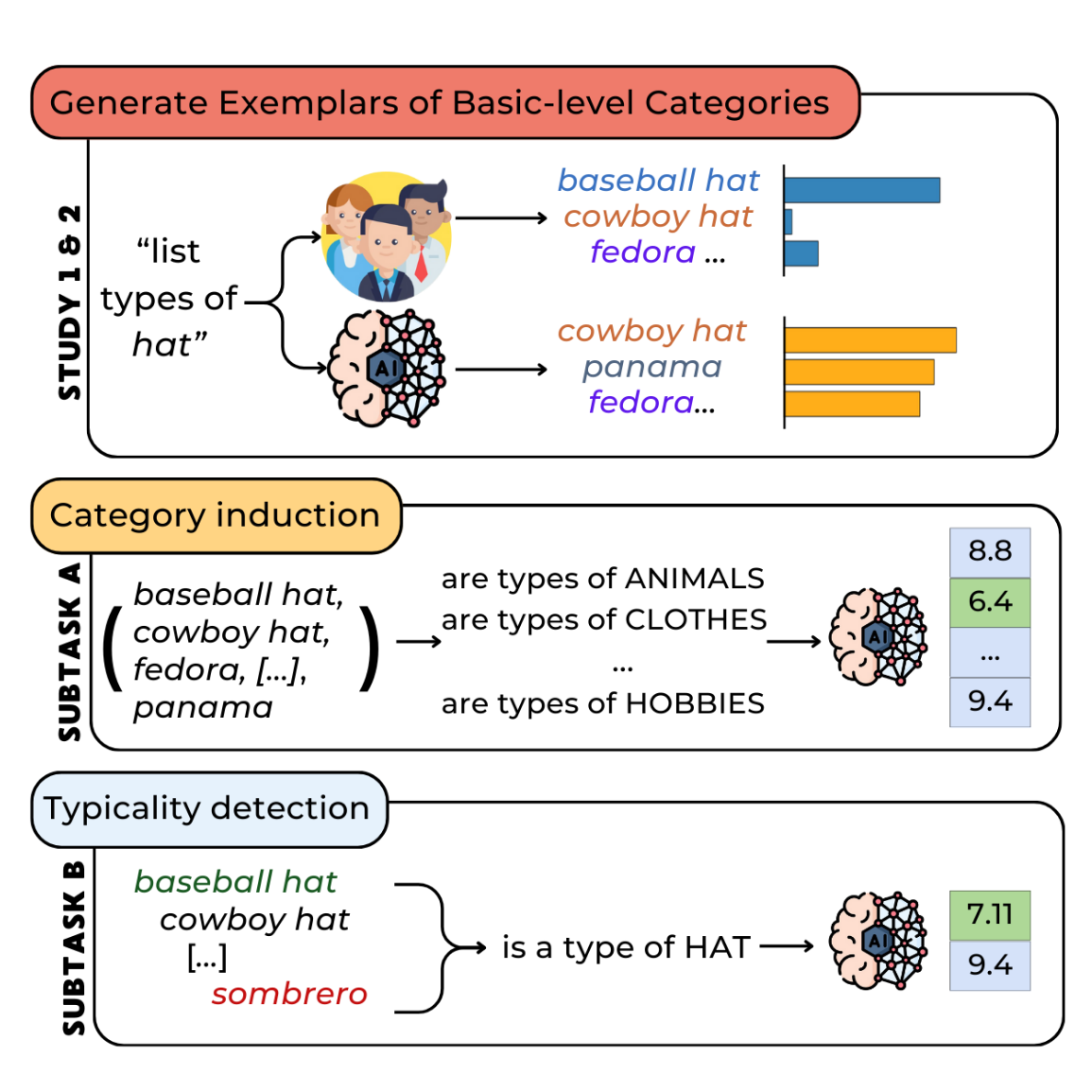 How Humans and LLMs Organize Conceptual Knowledge: Exploring Subordinate Categories in ItalianAndrea Pedrotti, Giulia Rambelli, Caterina Villani, and 1 more authorIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Jul 2025
How Humans and LLMs Organize Conceptual Knowledge: Exploring Subordinate Categories in ItalianAndrea Pedrotti, Giulia Rambelli, Caterina Villani, and 1 more authorIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Jul 2025People can categorize the same entity at multiple taxonomic levels, such as basic (bear), superordinate (animal), and subordinate (grizzly bear). While prior research has focused on basic-level categories, this study is the first attempt to examine the organization of categories by analyzing exemplars produced at the subordinate level. We present a new Italian psycholinguistic dataset of human-generated exemplars for 187 concrete words. We then leverage these data to evaluate whether textual and vision LLMs produce meaningful exemplars that align with human category organization across three key tasks: exemplar generation, category induction, and typicality judgment. Our findings show a low alignment between humans and LLMs, consistent with previous studies. However, their performance varies notably across different semantic domains. Ultimately, this study highlights both the promises and the constraints of using AI-generated exemplars to support psychological and linguistic research.
- ACL
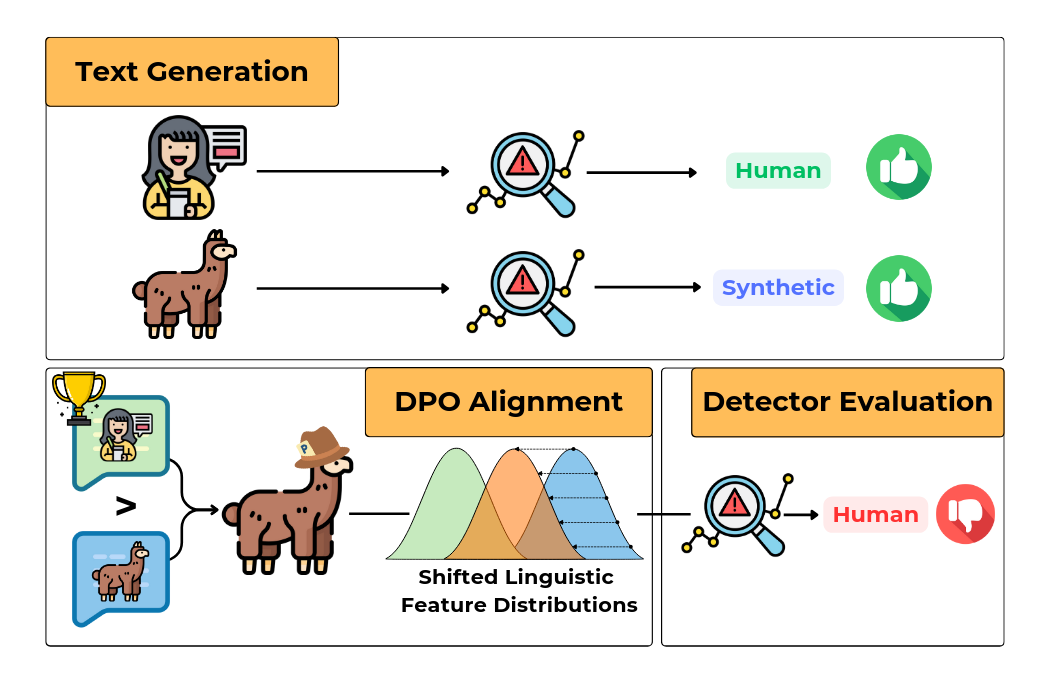 Stress-testing Machine Generated Text Detection: Shifting Language Models Writing Style to Fool DetectorsAndrea Pedrotti, Michele Papucci, Cristiano Ciaccio, and 4 more authorsIn Findings of the Association for Computational Linguistics: ACL 2025, Jul 2025
Stress-testing Machine Generated Text Detection: Shifting Language Models Writing Style to Fool DetectorsAndrea Pedrotti, Michele Papucci, Cristiano Ciaccio, and 4 more authorsIn Findings of the Association for Computational Linguistics: ACL 2025, Jul 2025Recent advancements in Generative AI and Large Language Models (LLMs) have enabled the creation of highly realistic synthetic content, raising concerns about the potential for malicious use, such as misinformation and manipulation. Moreover, detecting Machine-Generated Text (MGT) remains challenging due to the lack of robust benchmarks that assess generalization to real-world scenarios. In this work, we evaluate the resilience of state-of-the-art MGT detectors (e.g., Mage, Radar, LLM-DetectAIve) to linguistically informed adversarial attacks. We develop a pipeline that fine-tunes language models using Direct Preference Optimization (DPO) to shift the MGT style toward human-written text (HWT), obtaining generations more challenging to detect by current models. Additionally, we analyze the linguistic shifts induced by the alignment and how detectors rely on “linguistic shortcuts” to detect texts. Our results show that detectors can be easily fooled with relatively few examples, resulting in a significant drop in detecting performances. This highlights the importance of improving detection methods and making them robust to unseen in-domain texts. We release code, models, and data to support future research on more robust MGT detection benchmarks.
- NAACL
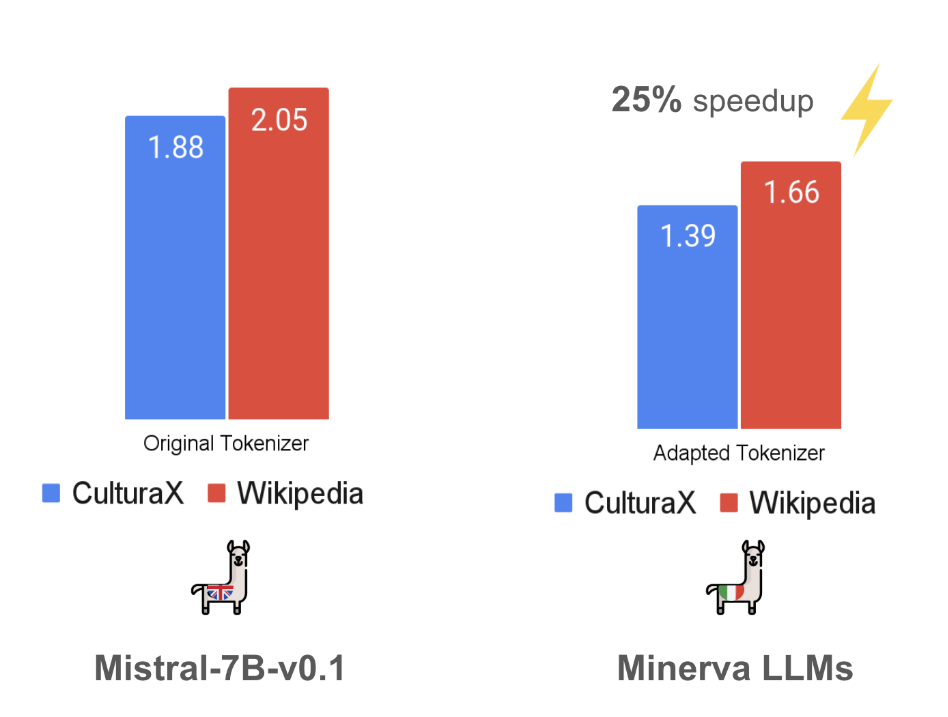 Optimizing LLMs for Italian: Reducing Token Fertility and Enhancing Efficiency Through Vocabulary AdaptationLuca Moroni, Giovanni Puccetti, Pere-Lluís Huguet Cabot, and 6 more authorsIn Findings of the Association for Computational Linguistics: NAACL 2025, Apr 2025
Optimizing LLMs for Italian: Reducing Token Fertility and Enhancing Efficiency Through Vocabulary AdaptationLuca Moroni, Giovanni Puccetti, Pere-Lluís Huguet Cabot, and 6 more authorsIn Findings of the Association for Computational Linguistics: NAACL 2025, Apr 2025The number of pretrained Large Language Models (LLMs) is increasing steadily, though the majority are designed predominantly for the English language. While state-of-the-art LLMs can handle other languages, due to language contamination or some degree of multilingual pretraining data, they are not optimized for non-English languages, leading to inefficient encoding (high token “fertility”) and slower inference speed.In this work, we thoroughly compare a variety of vocabulary adaptation techniques for optimizing English LLMs for the Italian language, and put forward Semantic Alignment Vocabulary Adaptation (SAVA), a novel method that leverages neural mapping for vocabulary substitution. SAVA achieves competitive performance across multiple downstream tasks, enhancing grounded alignment strategies. We adapt two LLMs: Mistral-7B-v0.1, reducing token fertility by 25%, and Llama-3.1-8B, optimizing the vocabulary and reducing the number of parameters by 1 billion. We show that, following the adaptation of the vocabulary, these models can recover their performance with a relatively limited stage of continual training on the target language. Finally, we test the capabilities of the adapted models on various multi-choice and generative tasks.
- GWC
 Wordnet and Word Ladders: Climbing the abstraction taxonomy with LLMsGiovanni Puccetti, Andrea Esuli, and Marianna BolognesiIn Proceedings of the 13th Global Wordnet Conference, Jan 2025
Wordnet and Word Ladders: Climbing the abstraction taxonomy with LLMsGiovanni Puccetti, Andrea Esuli, and Marianna BolognesiIn Proceedings of the 13th Global Wordnet Conference, Jan 2025WordNet has long served as a benchmark for approximating the mechanisms of semantic categorization in the human mind, particularly through its hierarchical structure of word synsets, most notably the IS-A relation. However, these semantic relations have traditionally been curated manually by expert lexicographers, relying on external resources like dic- tionaries and corpora. In this paper, we explore whether large language models (LLMs) can be leveraged to approximate these hierarchical semantic relations, potentially offering a scalable and more dynamic alternative for maintaining and updating the WordNet taxonomy. This investigation addresses the feasibility and implications of automating this process with LLMs by testing a set of prompts encoding dif- ferent sociodemographic traits and finds that adding age and job information to the prompt affects the model ability to generate text in agreement with hierarchical semantic relations while gender does not have a statistically significant impact.
- COLING
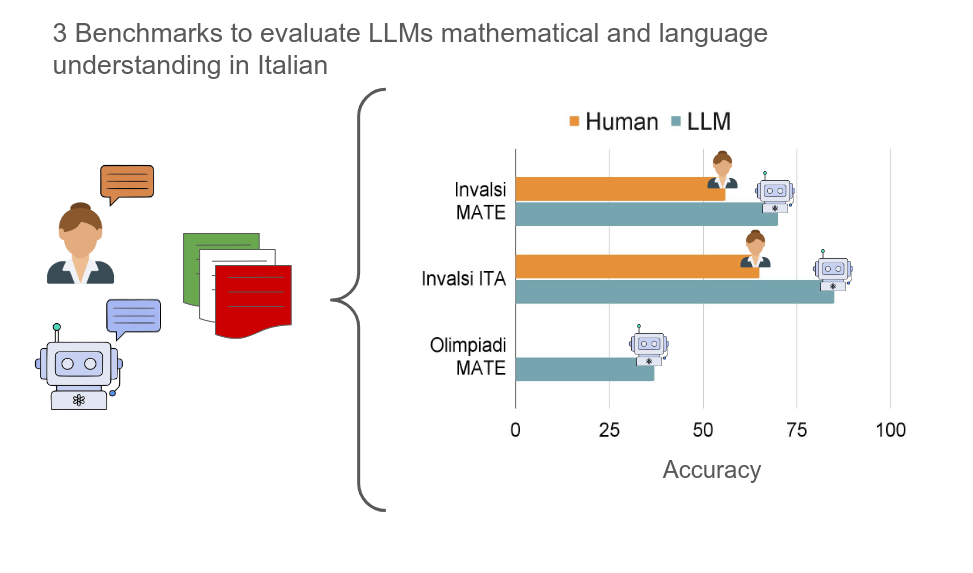 The Invalsi Benchmarks: measuring the Linguistic and Mathematical understanding of Large Language Models in ItalianGiovanni Puccetti, Maria Cassese, and Andrea EsuliIn Proceedings of the 31st International Conference on Computational Linguistics, Jan 2025
The Invalsi Benchmarks: measuring the Linguistic and Mathematical understanding of Large Language Models in ItalianGiovanni Puccetti, Maria Cassese, and Andrea EsuliIn Proceedings of the 31st International Conference on Computational Linguistics, Jan 2025While Italian is a high-resource language, there are few Italian-native benchmarks to evaluate generative Large Language Models (LLMs) in this language. This work presents three new benchmarks: Invalsi MATE to evaluate models performance on mathematical understanding in Italian, Invalsi ITA to evaluate language under standing in Italian and Olimpiadi MATE for more complex mathematical understanding. The first two benchmarks are based on the Invalsi tests, which are administered to students of age between 6 and 18 within the Italian school system and have been validated by several experts in teaching and pedagogy, the third one comes from the Italian highschool math Olympics. We evaluate 10 powerful language models on these benchmarks and we find that they are bound by 71% accuracy on Invalsi MATE, achieved by Llama 3.1 70b instruct and by 88% on Invalsi ITA. For both Invalsi MATE and Invalsi ITA we compare LLMs with the average performance of Italian students to show that Llama 3.1 is the only one to outperform them on Invalsi MATE while most models do so on Invalsi ITA, we then show that Olimpiadi MATE is more challenging than Invalsi MATE and the highest accuracy, achieved by Llama 3.1 405b instruct accuracy is 45%.
- EMNLP
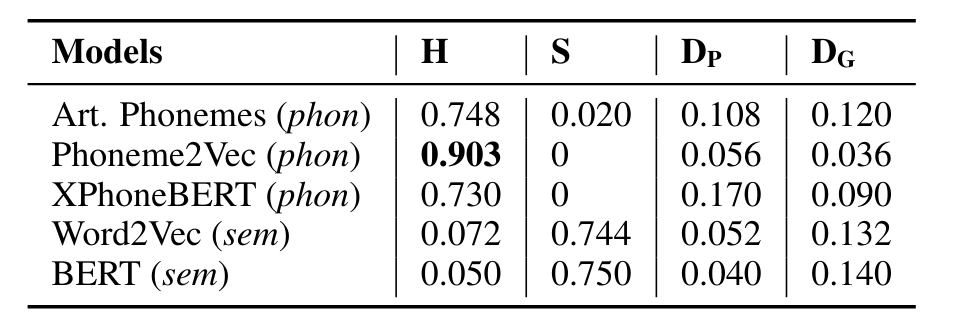 PSET: a Phonetics-Semantics Evaluation TestbedGianluca Sperduti and Dong NguyenIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Nov 2025
PSET: a Phonetics-Semantics Evaluation TestbedGianluca Sperduti and Dong NguyenIn Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Nov 2025We introduce the Phonetics-Semantics Evaluation Testbed (PSET), a new English-based testbed to evaluate phonetic embeddings. Our testbed is built on the assumption that phonetic embeddings should always prioritize phonetics over semantics, and it therefore leverages homophones and synonyms.We use PSET to test three phonetic embedding models: articulatory embeddings, Phoneme2Vec, and XPhoneBERT. The phonetic-based embeddings solve the task with varying degrees of success, with Phoneme2Vec performing the best.We also test five recent LLMs, GPT-4o, Gemini 2.5 Flash, Llama 3.1-8B, OLMo-7B and OLMo 2-7B. Gemini 2.5 Flash performs better than the other models. With this testbed, we hope to advance the development and evaluation of phonetic embedding models.
- under review
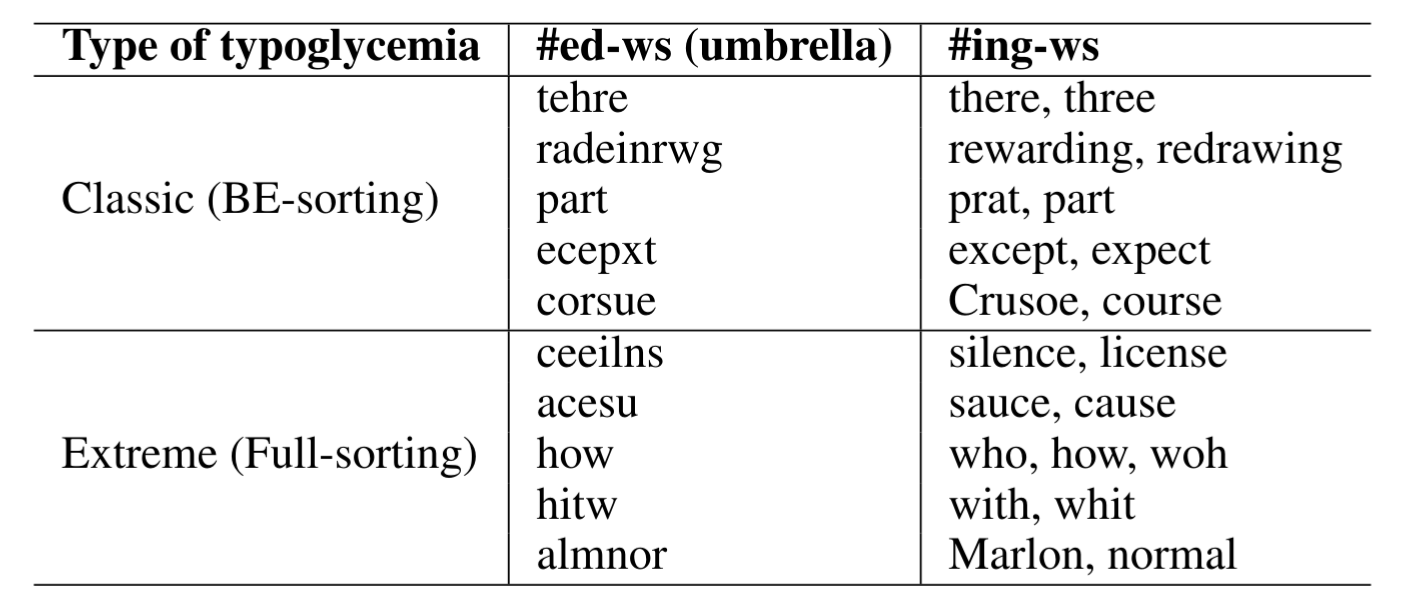 Typoglycemia under the Hood: Investigating Language Models’ Understanding of Scrambled WordsGianluca Sperduti and Alejandro MoreoNov 2025
Typoglycemia under the Hood: Investigating Language Models’ Understanding of Scrambled WordsGianluca Sperduti and Alejandro MoreoNov 2025Research in linguistics has shown that humans can read words with internally scrambled letters, a phenomenon recently dubbed typoglycemia. Some specific NLP models have recently been proposed that similarly demonstrate robustness to such distortions by ignoring the internal order of characters by design. This raises a fundamental question: how can models perform well when many distinct words (e.g., form and from) collapse into identical representations under typoglycemia? Our work, focusing exclusively on the English language, seeks to shed light on the underlying aspects responsible for this robustness. We hypothesize that the main reasons have to do with the fact that (i) relatively few English words collapse under typoglycemia, and that (ii) collapsed words tend to occur in contexts so distinct that disambiguation becomes trivial. In our analysis, we (i) analyze the British National Corpus to quantify word collapse and ambiguity under typoglycemia, (ii) evaluate BERT’s ability to disambiguate collapsing forms, and (iii) conduct a probing experiment by comparing variants of BERT trained from scratch on clean versus typoglycemic Wikipedia text; our results reveal that the performance degradation caused by scrambling is smaller than expected.
- under review
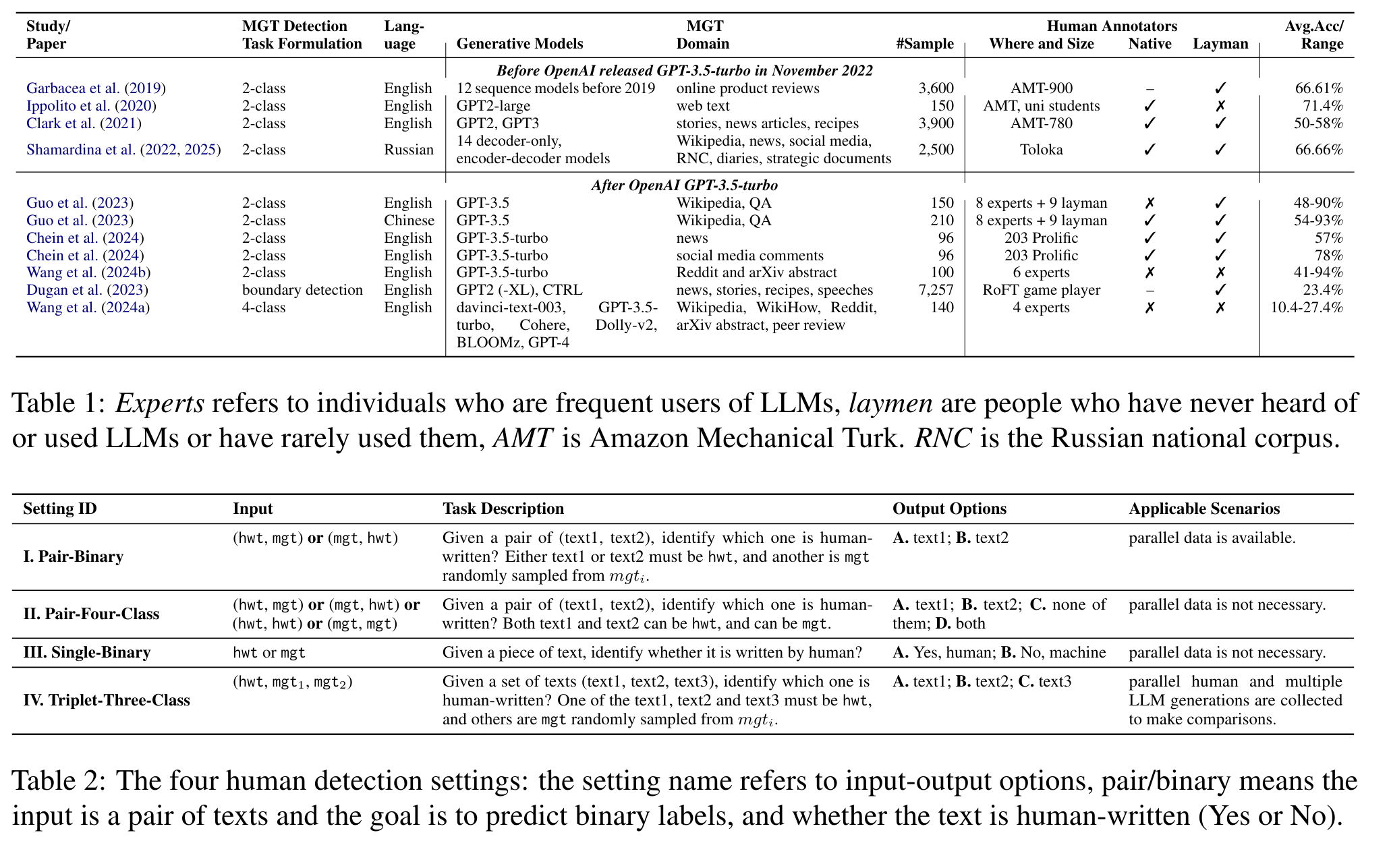 Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against AIYuxia Wang, Rui Xing, Jonibek Mansurov, and 23 more authorsNov 2025
Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against AIYuxia Wang, Rui Xing, Jonibek Mansurov, and 23 more authorsNov 2025Prior studies have shown that distinguishing text generated by large language models (LLMs) from human-written one is highly challenging, and often no better than random guessing. To verify the generalizability of this finding across languages and domains, we perform an extensive case study to identify the upper bound of human detection accuracy. Across 16 datasets covering 9 languages and 9 domains, 19 annotators achieved an average detection accuracy of 87.6%, thus challenging previous conclusions. We find that major gaps between human and machine text lie in concreteness, cultural nuances, and diversity. Prompting by explicitly explaining the distinctions in the prompts can partially bridge the gaps in over 50% of the cases. However, we also find that humans do not always prefer human-written text, particularly when they cannot clearly identify its source.
- CogSci
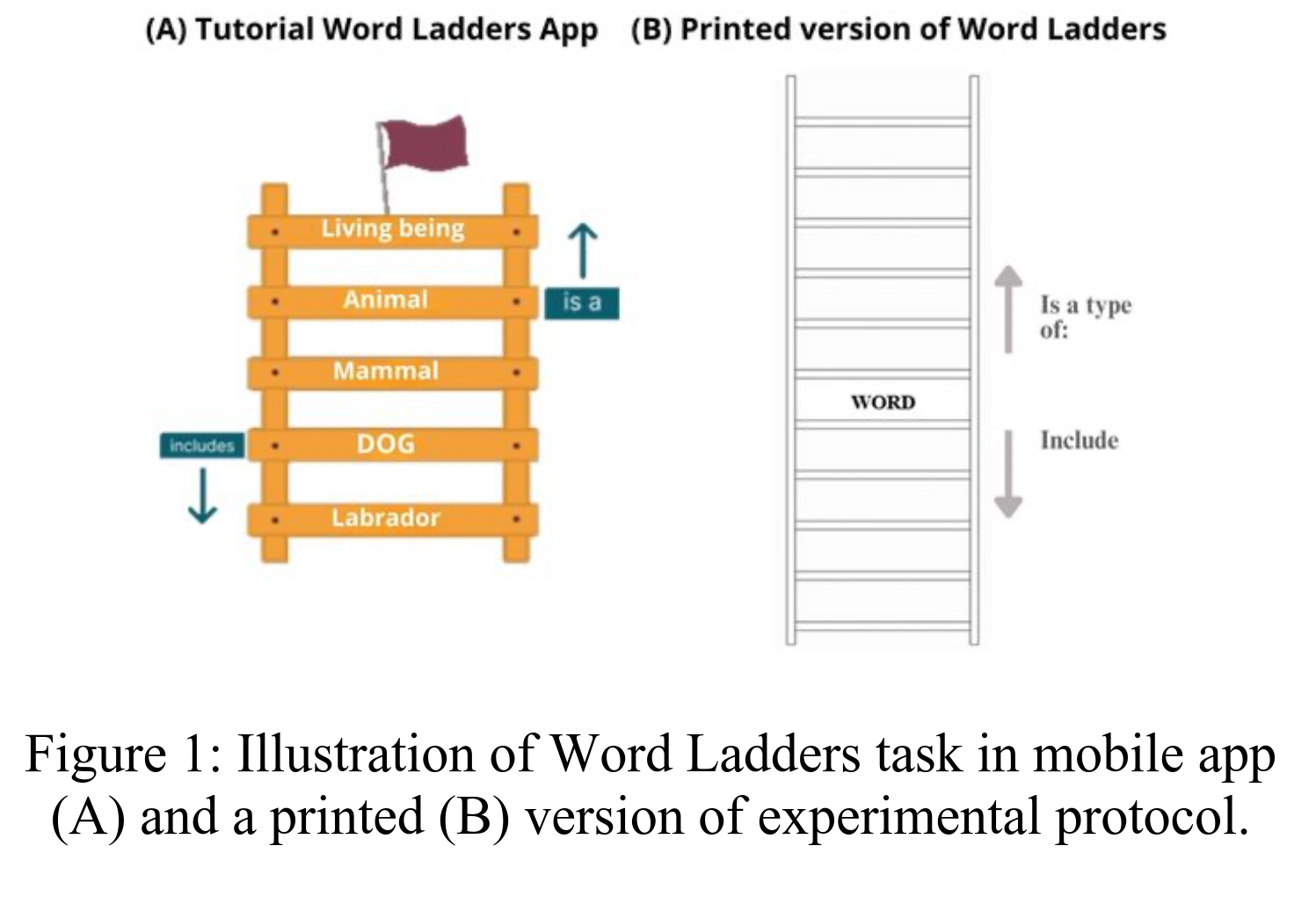 Development of Linguistic-Mediated Abstraction: Insights from Word Ladders taskCaterina Villani, Adele Loia, and Marianna M BolognesiIn Proceedings of the Annual Meeting of the Cognitive Science Society, Nov 2025
Development of Linguistic-Mediated Abstraction: Insights from Word Ladders taskCaterina Villani, Adele Loia, and Marianna M BolognesiIn Proceedings of the Annual Meeting of the Cognitive Science Society, Nov 2025What is the developmental trajectory of language-mediated abstraction skills, and to what extent are these skills influenced by semantics? We address these questions asking children to generate semantic relations of categorical inclusion for words varying in concreteness. Results show that abstraction improves over time, independent of age, with both concrete and abstract concepts organized into hierarchical taxonomies. However, abstract concepts allow shorter ladders, making them harder to categorize, especially for younger children. These findings underscore the distinction between concreteness and specificity as separate dimensions of abstract reasoning, and they lend empirical support to theoretical models that treat these facets of abstraction as dissociable.
- HHAI
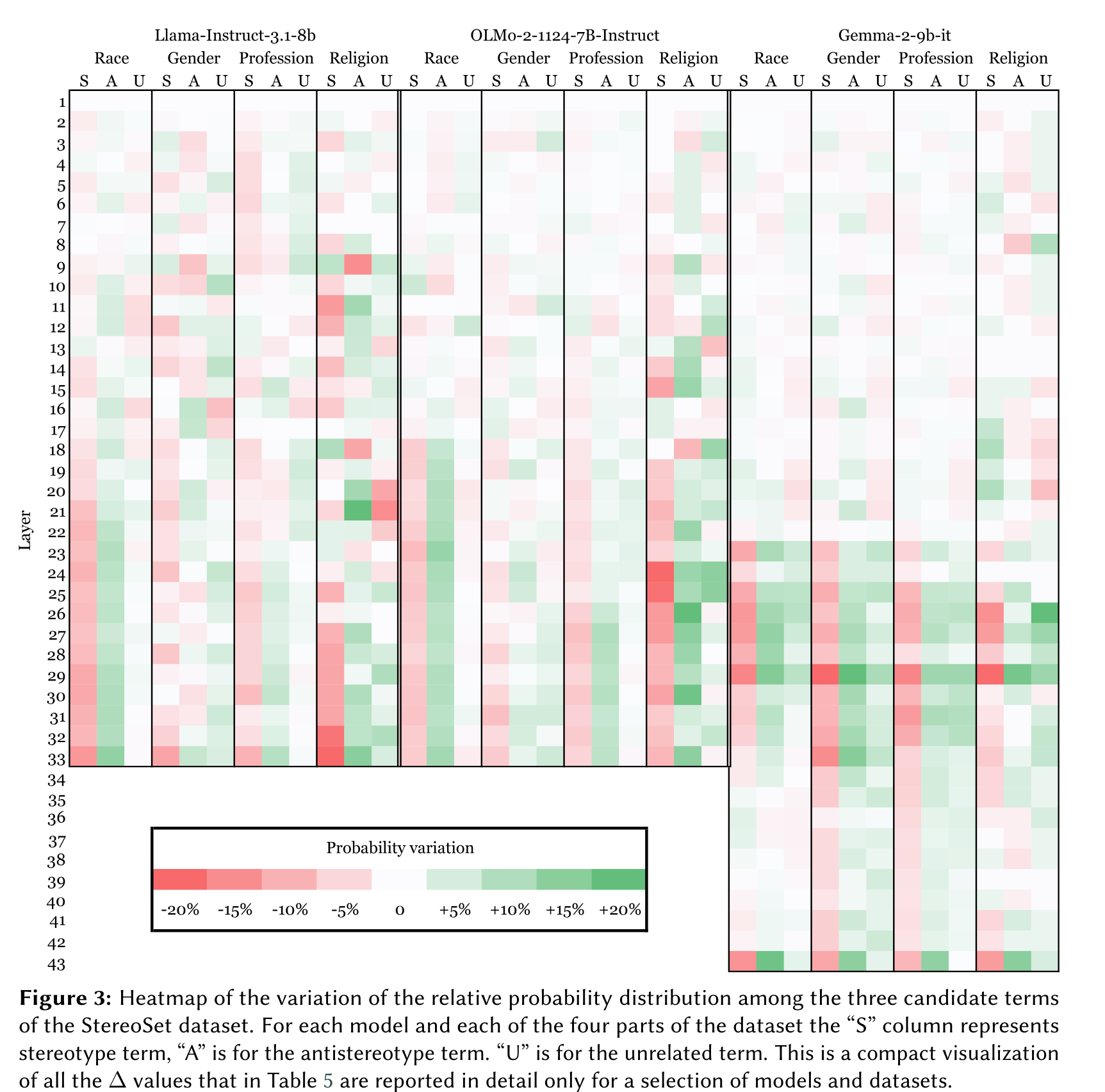 Prompt-based Bias Control in Large Language Models: A Mechanistic AnalysisMaria Cassese, Giovanni Puccetti, and Andrea EsuliIn Proceedings of the HHAI 2025 Workshop “Mind the AI-GAP 2025: Co-Designing Socio-Technical Systems”, Nov 2025
Prompt-based Bias Control in Large Language Models: A Mechanistic AnalysisMaria Cassese, Giovanni Puccetti, and Andrea EsuliIn Proceedings of the HHAI 2025 Workshop “Mind the AI-GAP 2025: Co-Designing Socio-Technical Systems”, Nov 2025This study investigates the role of prompt design in controlling stereotyped content generation in large language models (LLMs). Specifically, we examine how adding a fairness-oriented request in the prompt instructions influences both the output and internal states of LLMs. Using the StereoSet dataset, we evaluate models from different families (Llama, Gemma, OLMo) with base and fairness-focused prompts. Human evaluations reveal that models exhibit medium levels of stereotyped output by default, with a varying impact of fairness prompts on reducing it. We applied for the first time a mechanistic interpretability technique (Logit Lens) to the task, showing the depth of the impact of the fairness prompts in the stack of transformer layers, and finding that even with the fairness prompt, stereotypical words remain more probable than anti-stereotypical ones across most layers. While fairness prompts reduce stereotypical probabilities, they are insufficient to reverse the overall trend. This study is an initial dig into the analysis of the presence and propagation of stereotype bias in LLMs, and the findings highlight the challenges of mitigating bias through prompt engineering, suggesting the need for broader interventions on models
2024
- CLiC-it
 ABRICOT - ABstRactness and Inclusiveness in COntexT: A CALAMITA ChallengeGiovanni Puccetti, Claudia Collacciani, Andrea Amelio Ravelli, and 2 more authorsIn Proceedings of the Tenth Italian Conference on Computational Linguistics (CLiC-it 2024), Dec 2024
ABRICOT - ABstRactness and Inclusiveness in COntexT: A CALAMITA ChallengeGiovanni Puccetti, Claudia Collacciani, Andrea Amelio Ravelli, and 2 more authorsIn Proceedings of the Tenth Italian Conference on Computational Linguistics (CLiC-it 2024), Dec 2024The ABRICOT Task is designed to evaluate Italian language models on their ability to understand and assess the abstractness and inclusiveness of language, two nuanced features that humans naturally convey in everyday communication. Unlike binary categorizations such as abstract/concrete or inclusive/exclusive, these features exist on a continuous spectrum with varying degrees of intensity. The task is based on a manual collection of sentences that present the same noun phrase (NP) in different contexts, allowing its interpretation to vary between the extremes of abstractness and inclusiveness. This challenge aims to verify the how LLMs perceive subtle linguistic variations and their implications in natural language.
- ACL
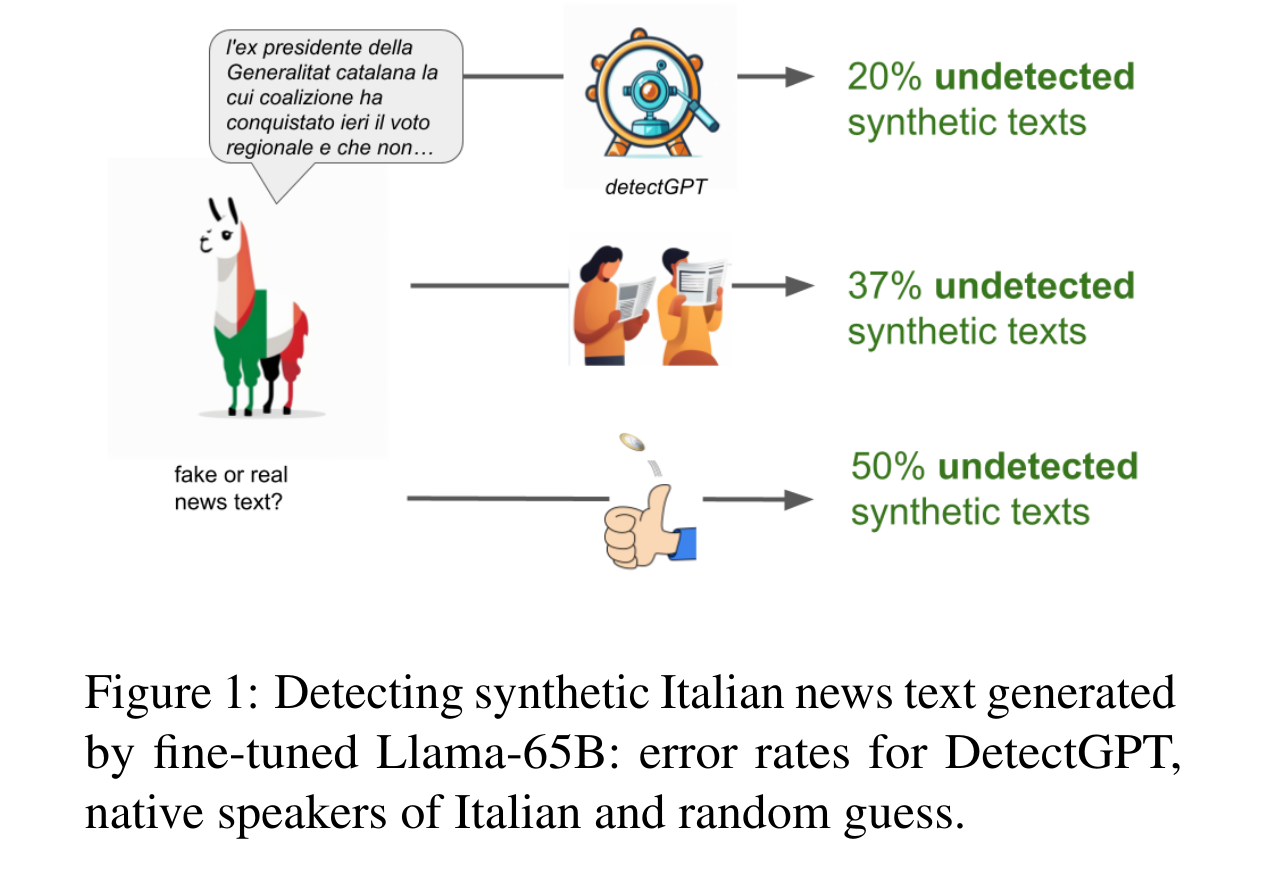 AI ‘News’ Content Farms Are Easy to Make and Hard to Detect: A Case Study in ItalianGiovanni Puccetti, Anna Rogers, Chiara Alzetta, and 2 more authorsIn Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Aug 2024
AI ‘News’ Content Farms Are Easy to Make and Hard to Detect: A Case Study in ItalianGiovanni Puccetti, Anna Rogers, Chiara Alzetta, and 2 more authorsIn Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Aug 2024Large Language Models (LLMs) are increasingly used as ‘content farm’ models (CFMs), to generate synthetic text that could pass for real news articles. This is already happening even for languages that do not have high-quality monolingual LLMs. We show that fine-tuning Llama (v1), mostly trained on English, on as little as 40K Italian news articles, is sufficient for producing news-like texts that native speakers of Italian struggle to identify as synthetic.We investigate three LLMs and three methods of detecting synthetic texts (log-likelihood, DetectGPT, and supervised classification), finding that they all perform better than human raters, but they are all impractical in the real world (requiring either access to token likelihood information or a large dataset of CFM texts). We also explore the possibility of creating a proxy CFM: an LLM fine-tuned on a similar dataset to one used by the real ‘content farm’. We find that even a small amount of fine-tuning data suffices for creating a successful detector, but we need to know which base LLM is used, which is a major challenge.Our results suggest that there are currently no practical methods for detecting synthetic news-like texts ‘in the wild’, while generating them is too easy. We highlight the urgency of more NLP research on this problem.
- CLiC-it
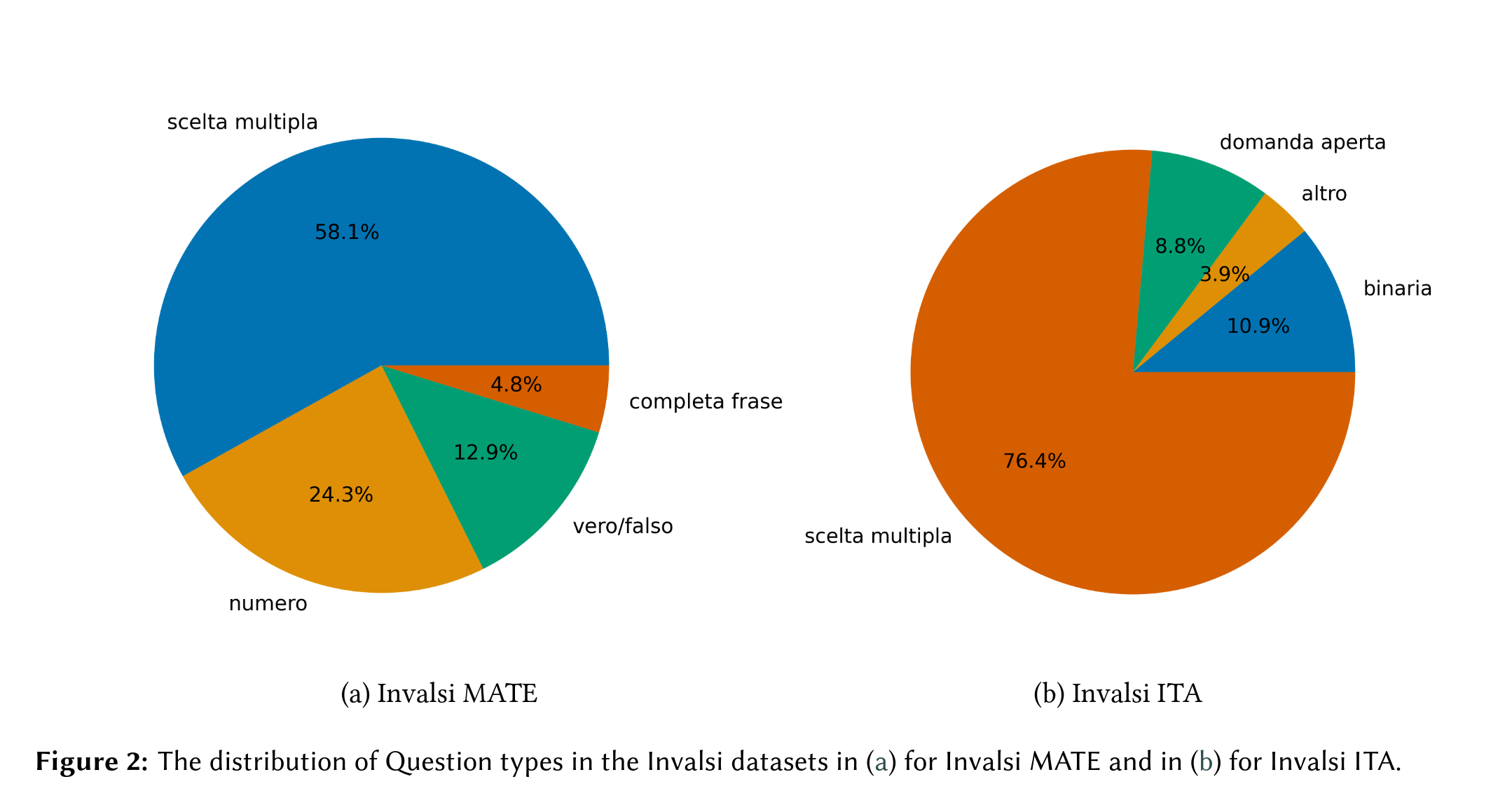 INVALSI - Mathematical and Language Understanding in Italian: A CALAMITA ChallengeGiovanni Puccetti, Maria Cassese, and Andrea EsuliIn Proceedings of the Tenth Italian Conference on Computational Linguistics (CLiC-it 2024), Dec 2024
INVALSI - Mathematical and Language Understanding in Italian: A CALAMITA ChallengeGiovanni Puccetti, Maria Cassese, and Andrea EsuliIn Proceedings of the Tenth Italian Conference on Computational Linguistics (CLiC-it 2024), Dec 2024While Italian is a high resource language, there are few Italian-native benchmarks to evaluate Language Models (LMs) generative abilities in this language. This work presents two new benchmarks: Invalsi MATE to evaluate models performance on mathematical understanding in Italian and Invalsi ITA to evaluate language understanding in Italian.These benchmarks are based on the Invalsi tests, which are administered to students of age between 6 and 18 within the Italian school system. These tests are prepared by expert pedagogists and have the explicit goal of testing average students’ performance over time across Italy. Therefore, the questions are well written, appropriate for the age of the students, and are developed with the goal of assessing students’ skills that are essential in the learning process, ensuring that the benchmark proposed here measures key knowledge for undergraduate students.Invalsi MATE is composed of 420 questions about mathematical understanding, these questions range from simple money counting problems to Cartesian geometry questions, e.g. determining if a point belongs to a given line. They are divided into 4 different types: scelta multipla (multiple choice), vero/falso (true/false), numero (number), completa frase (fill the gap). Invalsi ITA is composed of 1279 questions regarding language understanding, these questions involve both the ability to extract information and answer questions about a text passage as well as questions about grammatical knowledge. They are divided into 4 different types: scelta multipla (multiple choice), binaria (binary), domanda aperta (open question) and altro (other).We evaluate 4 powerful language models both English-first and tuned for Italian to see that best accuracy on Invalsi MATE is 55% while best accuracy on Invalsi ITA is 80%.